
Liquid Clustering vs. Hive-Clustering and Z-Ordering
Why it's a game changer and why you should implement it for your data

Databricks announced yesterday the General Availability of Liquid Clustering. An Out-of-the-box, self-tuning data layout that scales with your data.
So what is Liquid Clustering?
In this article, I give you a high-level explanation of clustering, different methodologies and why Liquid Clustering is a game changer.

Let’s be honest. We all want a query to run fast. By the current standard, I interrupt my query as soon as it takes a while and it still has not delivered the goods. Did I make a mistake with some join? Is there an order by i accidentally left out there?
Most of the time it comes down to the quantity of rows you’re preprocessing. However, you are allowed to have big tables, you should be. I mean why not. And that’s where table partitioning your data comes in.
Caveats of Traditional Clustering
In the case of partitioning and Z-Order, you are bound by fixed data structures. However, Liquid Clustering gives you the flexibility you need in case of frequent changes in clustering keys. In a way, you don’t have to adjust your ever evolving data, it adjusts incrementally based on your data.
Challenge 1: Choosing the Right Partitioning Strategy
Deciding on the best partitioning strategy is difficult. If partition columns are not chosen well, it leads to slower reads and poor query performance due to file sizes being too big or too small.
Challenge 2: Expensive and Time-Consuming ZORDERing Jobs
ZORDERing can speed up reads, but it makes writes take much much longer and costs more because it isn't incremental and can't be done during writing. It also doesn't optimize data across the whole dataset, which limits query performance.
Challenge 3: Constraints from Concurrent Write Needs
Partitioning strategies are limited by the need to write to the table at the same time. This results in partitions based on columns that may not need it, requiring ongoing maintenance and data rewrites as query patterns change. Concurrent writes within the same partition are also not possible.
Liquid Clustering
There are certain point you need to mind if you’re using Databricks Liquid Clustering for you to take the full advantage of this feature:
You’re required to have Databricks Runtime 13.3 or above.
Your tables have high cardinality columns.
Significant skew in data distribution.
Your data grow quickly and change over a certain period of time.
Databricks conducted a benchmark using a standard 1 TB data warehouse workload to evaluate performance of Liquid Clustering against other traditional metholodgies. Liquid Clustering demonstrated 2.5 times faster clustering compared to Z-order. In this test, traditional Hive-style partitioning was significantly slower, mainly due to the costly shuffle process needed to write out multiple partitions.
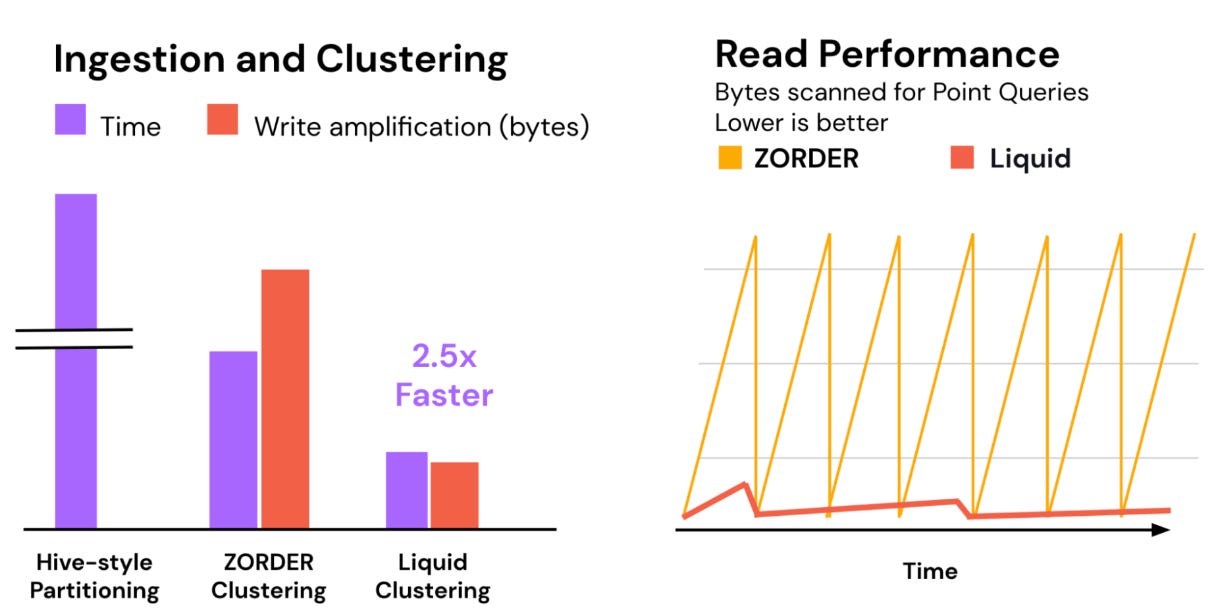
In the illustration above, you can see that in reading AND writing Liquid Clustering outperforms both Hive-Partitioning and Z-Order Clustering.
The best part: It is quite easy to implement!
Essentially, all you need is to use the following code to create a new table and cluster it by:
CREATE TABLE table_purchases(invoice_ts timestamp, invoice_id int) CLUSTER BY (invoice_ts);As you can see we can easily cluster by timestamp or here in our example by the invoice_ts. Contrary to hive-clustering, we aren’t required to create another column with the year in it, in order to cluster by the year. That alone is a huge advantage.
After you have partitioned your data, you can use the optimize function to trigger clustering:
OPTIMIZE table_name;For optimal performance, Databricks advises setting up regular optimize jobs to cluster data. For tables that undergo frequent updates or inserts, it is recommended to schedule an optimize job every one to two hours. Due to the incremental nature of liquid clustering, most optimize jobs for clustered tables complete quickly.
Here’s another example you can use in PySpark:
# Create an empty table
(DeltaTable.create()
.tableName("table1")
.addColumn("col0", dataType = "INT")
.addColumn("col1", dataType = "STRING")
.clusterBy("col0")
.execute())
# Using a CTAS statement
df = spark.read.table("table1")
df.write.format("delta").clusterBy("col0").saveAsTable("table2")
# CTAS using DataFrameWriterV2
df = spark.read.table("table1")
df.writeTo("table1").using("delta").clusterBy("col0").create()If you already have an exisiting table and you’d like to apply Liquid Clustering, you can use the following commands:
ALTER TABLE existing_table
SET TBLPROPERTIES ('delta.enableDeletionVectors' = false);ALTER TABLE existing_table
CLUSTER BY (clustering_columns)In summary, Liquid Clustering in Databricks optimizes data organization and boosts performance. It offers cost-effective, incremental clustering with minimal write amplification, resulting in faster write times and consistently quick read performance. For managing large datasets efficiently, Liquid Clustering is an essential tool. Embrace it to enhance your data workflows and maintain optimal performance.