
Evolution of Data Architecture
A brief history of the recent data buzzwords

Before diving into data engineering, I was working as a Data Analyst and then studying Data Science, I had a few internships as a Data Scientist. Whether for a Data Analyst or Data Scientist, you want to get the data as clean and transformed as possible. At least for the data scientist to train the model. As an analyst, you’re usually getting bombarded by new ad hoc analyses you must make, so you usually are not paying much attention to where the data comes from. It’s the magic that the data engineers are delivering. Yet as I got more into data engineering, I had a brief moment and the responsibility to understand the terminology being thrown around. I came across the book Delta Lake: Up and Running from an O’Reilly Edition. I loved it. Being 100% honest, I did not read everything and skimmed through it, but I was impressed by how well structured it was. In the first chapter it gave a very good overview of the data world and the evolution of data over the last couple of decades. I thought I would recite some of the good work to get the word out there. I also stole some of their visuals.

I think even among skilled data peeps, there’s still some strings unattached in this regard. Doesn’t mean that they don’t know what they are doing, but there are so many buzzwords thrown around that it can get confusing sometimes, so confused. Trying to Google it will give back to you back a total nonsense (imo), you mostly get sponsored pages to visit or download the e-book, or some of the big websites with the best SEO will get the first couple of pages of Google. Using LLMs, opposite to the current view, is, in my opinion, not the right tool. Learning is about knowing stuff you don't know. I needed something I could rely on and just consume for hours and hours without prompting again and again. In summary, get the damn book. Read more books, prompt less. A little less prompting, a little more books, please. This piece of knowledge might be more worthy than what’s coming.
Data Warehouse
Let’s start with Data Warehouses. A long time ago, once upon a time, companies concluded that data is the real deal. Data was recognised as valuable for analysis and reporting purposes. You wanted your customer, products and other business entity tables, the whole 9 yards.
The solution was a data warehouse. A central space where all the data is cleaned, historised, in some cases also aggregated, stored and accessable to the consumer. You had data sources. Please have a look at the figure below.
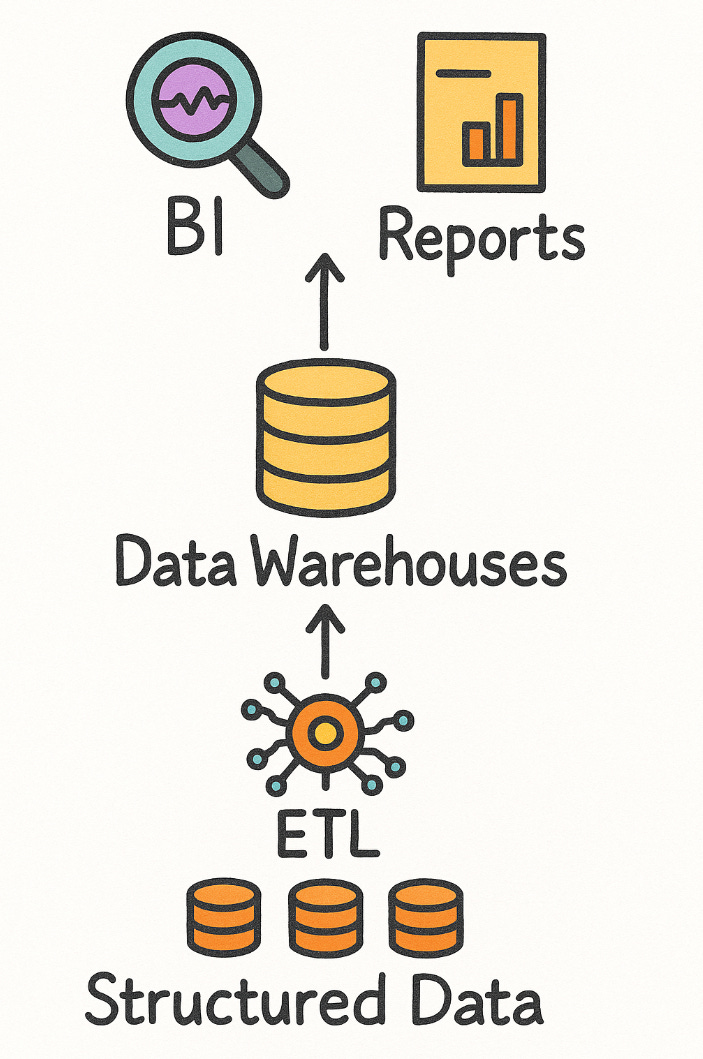
On the left, we have the source layer, which is a set of data sources that people inside and outside of the company use. Depending on your business and the nature of it, you have the CRM systems, the HR data, the operational data and more. Each of these, individually, has a different format. Some may come as CSV, some as a spreadsheet with a bunch of human-made errors in it, some less error-prone, some as JSON. To skip a couple of technical details and for the sake of simplicity, the data was extracted, loaded and transformed. This stage of the process includes multiple tasks such as elimination of duplicate records, correcting data formats and more quality checks to keep the data governance sane. From there, you have human data consumers: It ranges from workers with high domain knowledge to data analysts who use the data to build KPIS and dashboards to report. And you have system consumers: AI/ML tools, internal applications, APIs.
The little issue with Data Warehouse: The big Vs
Well, as time goes by, we have higher expectations. We want more data, faster, stronger, cleaner. In other words, the four Vs of data:
The amount of volume of data that is created, consumed globally is increasing rapidly. Today we expect data not only historical, we expect also near-live data. I guess that sounds a bit familiar to some of you who had to build live dashboards. Streaming data has become increasingly important for organisations with huge operations and supply chains to act quickly and make super-fast decisions to be more efficient.
Nowadays, the data is not only integers, and strings. Its not only rows and columns. You have device messages that comes in all sort of formats, audio, video, all sort of things. Lastly, of course, all of this would worth nothing if it wouldn’t come with Vercity: quality, accuracy and trustworthiness of the data. You need metadata, no missing data nor late-arrivals or delays.
Well, as you can derive from the structure of this article, Data Warehouse cannot deliver here. Traditional DWH struggles when data volume explodes.
Traditional data warehouses combine memory, compute, and storage in a single architecture. Therefore, companies have to scale vertically by upgrading entire systems, which is very inefficient, because you need that high-capacity capability and power during your peak. The rest of the time, it’s just idle. It’s like buying a Ferrari and driving once a year past 120 km/h with it. I mean, there are more reasons to buy one for many people, but you know what I am saying. The inability to scale components independently creates cost inefficiencies, as companies must upgrade the entire system even when only needing more of one resource. Moreover, most data warehouses are based on SQL-based query tools, which is not bad; it gets the job done if you want to analyse data and report a bit, but it’s, let’s say, not optimum for data scientists and machine learning models. Entering the next age: Data Lake.
Data Lake
A data lake is simply a repository where you store all of your data, structures, semi-structured, and unstructured, at any scale. Mostly in the form of files and blobs. At the beginning, the organisation where implementing and building a data lake for big data, yet all on-premise. That means you need to use Apache Hadoop and MapReduce to distribute the workload. In the mid-2010s, cloud data lakes started to appear. Simple Storage Service (S3) from Amazon, Azure Data Lake Storage and Google Cloud Storage started to be the alternative, easier solution to on-prem. With better service-level agreements (SLAs), geo-replication, and cost-effective options for cold storage for data you probably won’t need to read every day.
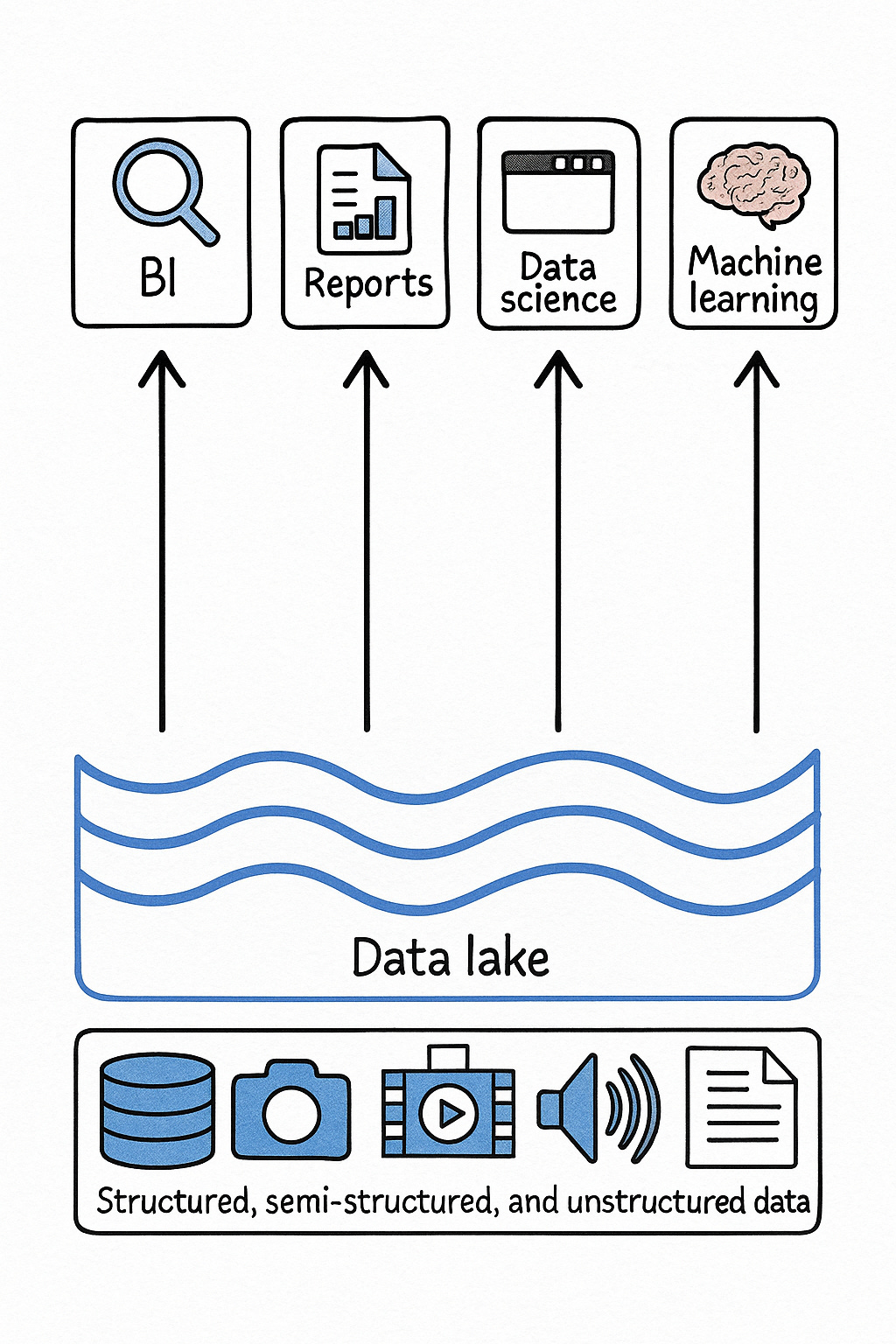
One of the core benefits of Data Lake is that it allows storage and compute to be separate, which allows for on-demand fine-tuning of resources. It’s like the U.S. Constitution: Separation of church and state. As data volumes grow, companies can expand storage capacity without necessarily upgrading compute resources and can adopt new processing technologies without migrating all their data. Different workloads often require different compute configurations, but now you're not stuck with one shared architecture. Furthermore, you have the freedom to use a wide array of file formats. Concerning Data Lakes, it’s mostly Parquets, JSONs or CSVs. In regards to metadata, Data Lakes allow you to maintain more of it more easily, as you don’t have to define a schema before actually recording metadata. For instance, Data Warehouses are like sorting items into specific boxes first, while Data Lakes are more like dumping everything in storage and organising afterwards. The first item might be seen as more tidy, but here is more about flexibility, which plays to your advantage when the future (Schema) is a bit unclear.
Yet the flexibility comes, obviously, with trade-offs. Where Data Warehouses operate on the “schema on write” strategy, Data Lakes use the “schema on read” game plan. For example, a data analyst working with Data Lakes might need to know how to flatten some of the files, whereas the counterpart using a Data Warehouse can use simple queries to obtain the data intended. As an example, a simple query could look like:
SELECT customer_id, AVG(rating)
FROM customer_feedback
GROUP BY customer_idOn the other hand, in Data Lake, you might need the following for the same results:
SELECT
CASE
WHEN json_extract_path(data, 'metadata', 'source') = 'web' THEN json_extract_path(data, 'user', 'id')
WHEN json_extract_path(data, 'metadata', 'source') = 'app' THEN json_extract_path(data, 'user_details', 'customer_id')
ELSE json_extract_path(data, 'customer', 'identifier')
END as customer_id,
AVG(
CASE
WHEN json_extract_path(data, 'metadata', 'source') = 'web' THEN CAST(json_extract_path(data, 'feedback', 'stars') AS FLOAT)
WHEN json_extract_path(data, 'metadata', 'source') = 'app' THEN CAST(json_extract_path(data, 'rating') AS FLOAT)
ELSE NULL
END
) as avg_rating
FROM raw_feedback
GROUP BY 1This example above is just an example which shows how “schema on read” requires analysts to have stronger programming skills, deeper understanding of data formats and the ability to handle inconsistencies and exceptions directly in their analysis code, rather than having these issues handled by data engineers earlier in the process.
Well the problem is not only that analyst have a more difficult time to query data and you might need to have more technical data nalyst than usual, the problem also is the possibility of Data Lake becoming a “data swamp”.
Introducing the whole mighty: Data Lakehouse
In 2021, a bunch of colleagues came together and wrote the article “Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics”. You can find the link to the paper here. In the paper, they argued that “data warehouse architecture as we know it today will wither in the coming years and be replaced by a new architectural pattern, the Lakehouse, which will (i) be based on open direct-access data formats, such as Apache Parquet, (ii) have firstclass support for machine learning and data science, and (iii) offer state-of-the-art performance. Lakehouses can help address several major challenges with data warehouses, including data staleness, reliability, total cost of ownership, data lock-in, and limited use-case support”. Furthermore, they defined a lakehouse as “a data management system based upon low-cost and directly accessible storage that also provides analytics DBMS management and performance features such as ACID transactions, data versioning, auditing, indexing, caching and query optimization”. Meaning you get the flexibility, cost-effectiveness, and scale of a data lake with the reliability of a data warehouse, which forces ACID transactions and some of the limitations of a Data Lake we discussed before.
A Data Lakehouse is like a storage system that combines the flexibility of the data lake with the structure and reliability of the warehouse in one shot.
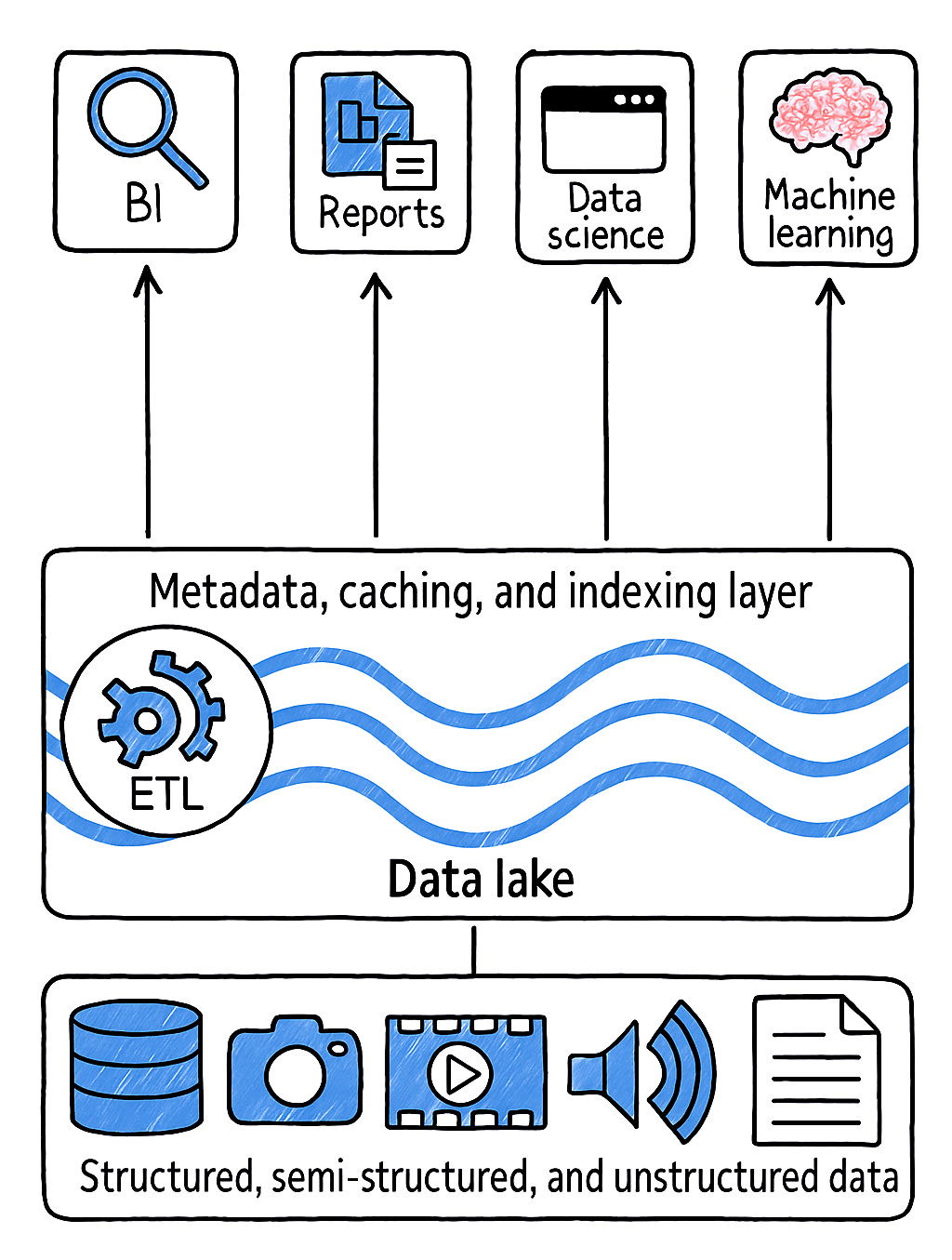
For the Lakehouse to implement ACID transactions, it requires a metadata layer on top of the storage to defining which objects are part of the table version. Data Lakehouse can be built on top of Delta Lake which is a open source framework and combines metadata, caching and indexing with a data lake storage format. Delta Lake serves as the storage layers, offers ACID for data consistency, transparency and quality and runs on top of cloud storage i.e. Ayure Storage, AWS S3 or GCP Storage.
Closing Thoughts
This article was simply there to have an understanding of how Data Lake and Data Lakehouse came about. What they mean, and essentially why they exist. I had already posted in regards to transaction logs and time travel in Delta Lake, which is one of the major benefits of Delta Lake Architecture. However, the best is yet to come: Shortly, I will dive deeper into Data Lakehouse.
You can find my detailed explanation of transaction logs here:
The Transaction Log: Delta Lake's Hidden Superpower

I have been exposed to Databricks over 2 years by now and although I have been here for a bit of time, it feels great to find out more features as the time goes. Databricks has been quite game changing for me and I think it's a tool that many businesses need to explore to see if it would fit their needs.